Researcher, Supervised by Professor Robert Pless
•Used Resnet/ViT to predict the time for one steady camera and for the trained model;
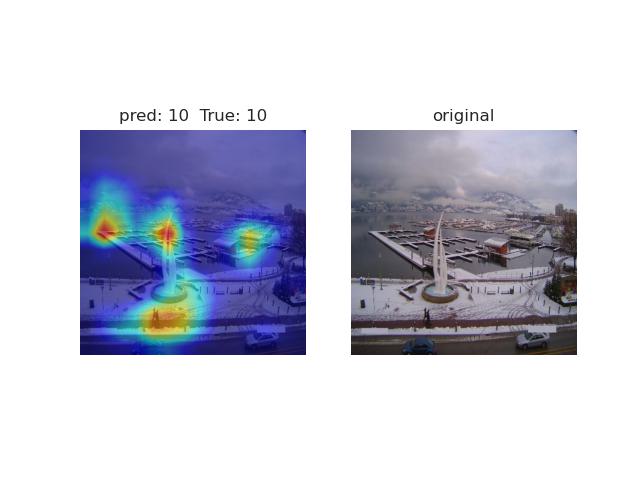
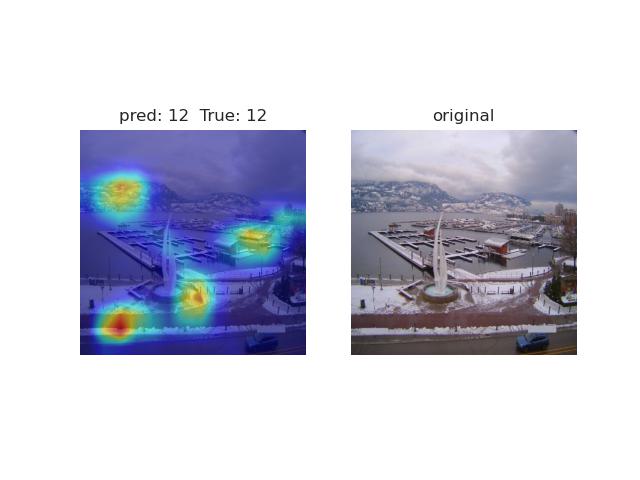
•Visualized the attention of the model by using GradCAM and heatmap;
•Predicted the time information in the picture under a given camera with the improved ViT;
•Extracted q and k for each batch, multiplied them together and showed them in the heatmap to see how the time changes;
•Tracked how the model detected time through the ViT and visualized temporal information within the probe model;
•Made oral representation at AIPR(IEEE workshop).
here is one of our visualization sites